
多智能体(multi-agent)运行听起来很诱人,因为它能让我们感受到效率的提升是几何倍数的增长。在我实践一番后发现,它的意义不仅仅在效率提升,更重要的是在于输出质量的提升,也在于 AI Coding 工作方式的升级。
畏难情绪
一开始听到多智能体会感觉比较复杂。毕竟想要让多个 Agent 并行工作,并不是一件容易的事。总感觉实现起来有点麻烦,所以一拖再拖,没有去研究。
再一个是怕出问题。这么多 agent 在一起运行,总感觉容易出乱子。多 agent 就像一个团队,你要管理一个团队,管理好一个团队不是那么容易的事情,好多事要顾及。你需要他们之间相互配合,同时也要保证他们的工作相对独立,不能抢结果,否则会扰乱整个流程。
玩龙虾带来的启发
上周开始玩了一下龙虾,尝试着探索多 agent,结合官方文档问了一下,龙虾直接把整个多 agent 的逻辑讲得非常清楚。由于是纯玩,探索起来也就没那么大压力,我迈出了多智能体探索的第一步。
题外话 /btw
养龙虾可以学到很多,增加对智能体的理解我非常喜欢龙虾的一点在于:虽然它的配置文件看起来非常复杂,但是条理非常清晰。也许这就是为什么它能管理好不同 agent 的记忆规则,以及让他们保留鲜明的性格特征。如果你想玩好龙虾,一定要吃透每个 agent 的 workspace,用 Git 项目管理起来,每次变更你都能 track 动了哪些配置,以及哪些是有必要的信息。这是存在于冰山下的世界——主动管理编辑这些文件,你就是在真正的养龙虾。
实践案例 1: openclaw skill /publisher
我在我的一个 openclaw agent Ciri的 workspace/skills 里面创建了一个publisher,他通过调用多智能体写作完成任务。它会先调用一个 sub-agent 作家 去使用写作技能,根据我的口述内容生成一篇文章;然后会有另外一个 sub-agent 画家,从刚生成的文章提取信息,画两幅图:一个 featured image,一个 content image,用于插入在文章里面。最后再把前面两个智能体产生的工作成果,通过 REST API 的方式上传到 WordPress。当然还有很多细节的操作。以下是原始prompt:

这样一套流程跑下来,我惊讶地发现:通过文字就能实现丝滑的子智能体调用,一步到位。且不论文章或图片的质量,整个流程是跑通了。
编程工具应用
这样一番实践之后,我就开始在 Claude Code 还有 Open Code 里面去实践。不管是国产模型还是海外的模型,有时候会自动触发 sub agent,特别是 Claude Code。后来我也试了一下 agent team 的功能,效果很惊艳
我想如果我能把这些多 agent 的能力主动带入到我的工作中——比如在一个 skill 中调用多个 agent 去执行任务,就像龙虾那样——这个底层逻辑与编程工具上面的实践是差不多的。所以如果我能把这些调用 sub agent、multi agent 的能力集成到我的 skill 或者工作流中,就会带来增益和更好的效果。
实践案例 2:claude skill /teamup
结合claude agent team的功能,我创建了一个skill: teamup, 根据任务描述自动生成agent team的设计,这样你只需要提需求,然后他会设计创建一个team,下面是这个/teamup skill 的主要设计思路。

/teamup 会根据官方建议的best-practice,当然也有我自己加进去的一些模式,因为在我看来即使是线性的任务也有必要创建多agents协同,后文会说明原因,下面再展示一下我的一个实际的复杂场景的团队执行计划:

实践案例 3:opencode comman /tool-explore
下面是我了解如何后,尝试的第一个同步调用多agents的应用场景。每天接触各种各样的优秀工具,可以说这是 AI 时代最重复的一个动作了。这个指令会对一个github项目进行4 个方向的同步探索,包括调用搜索工具安全检查,了解项目是做什么的,检查当前机器的系统并找到对应安装方案,寻找用户使用说明。
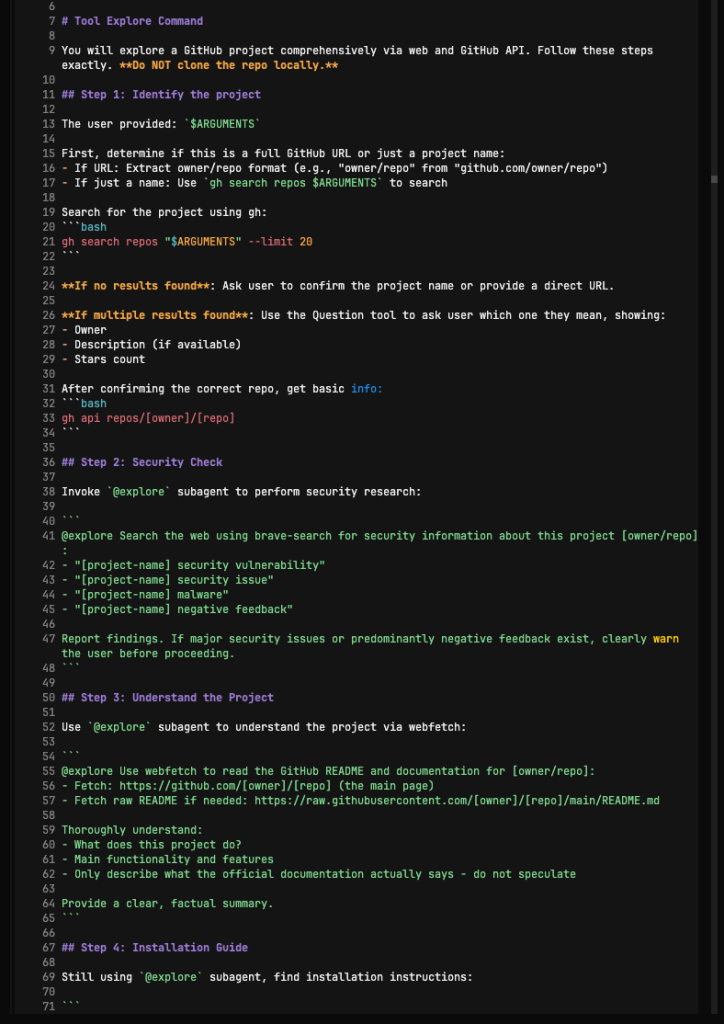
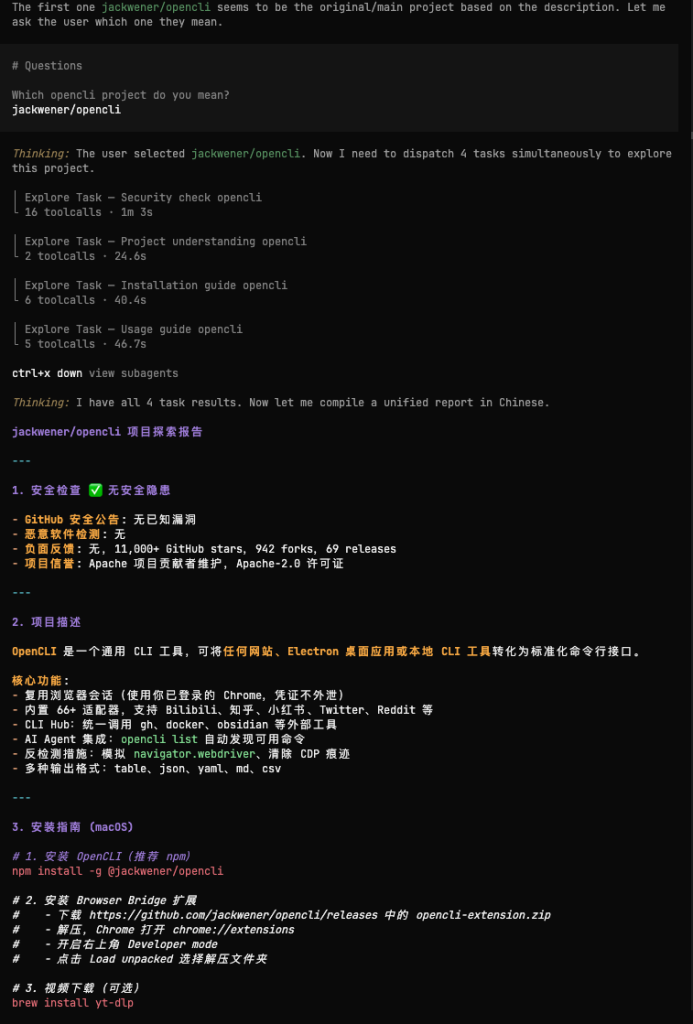
我附上了一篇智能体调用的说明可以参考,丢给大模型,然后创建skill的时候明确描述打算如何调用子智能体就可以了。不过是opencode的,如果你想在claude code里使用,丢给他,让他用claude-code-guide就可以帮你输出一版claude code格式兼容的版本。
多智能体的思考
结合实践与反思,我尝试用一个更系统的框架来整理对多智能体的理解。
- 线性工作流中的效率问题
在真实的项目开发中,大多数任务本质上是一条线性流水线——第一步完成后才能进入第二步,不可跳序。以瓷器烧制为例:挖土、筛土、加水、塑形、烧制,每一步都依赖前一步的输出。这种串行特性决定了即使引入多 Agent,也无法带来几何倍数的效率提升。
真正能实现并行效率的场景,是多套设备做相同的事——就像工厂多条流水线同时运行,产量翻倍。但面对一份从 0 到 1 的任务,并行没有意义。
- 为什么线性流程中仍然需要 sub-Agent
既然效率无法并行提升,引入 多个Agent 的价值何在?答案在于输出质量的稳定性。
每个 Agent 都存在注意力机制的上下文限制,不可能无限膨胀。当一个任务被拆分成几十个步骤时,单个 Agent 的专注度会随上下文膨胀而下降,最终产出质量的滑坡几乎是必然的。
解决思路来自于工业管理的一个经典范式——福特的流水线。福特将一个工人完成所有工序改为每个工人专注单一工种:只拧螺丝、只装零件、只做检测。这种分工让每个节点的产出质量都可控、可预期。
多 Agent 的分工逻辑与此一致:每个 Agent 专注流水线中的某一个模块,只对该模块的输出质量负责,拥有自己独立的上下文。 通过将长任务切分为多个独立子任务,每个 Agent 都能保持高专注度,最终再将各模块结果整合——这是线性工作流中多 Agent 最大的价值所在。如此我一个非常复杂的任务,在多轮对话后context只用了 20%,质量却丝毫没受影响。
- 并行探索:适合发散性任务
另一类场景则是截然不同的逻辑——研究性、探索性工作。这类任务的特点是发散的,不需要遵循固定的生产流程,更适合派出多个 sub-agent 同时探索。
打个比方:在荒野中搜索目标,一群人集中行动和分散搜索,哪个效率更高?显然是后者。并行 sub-agent 就像一个侦查小分队,信息面更广,命中率更高。但这类场景在日常工作中的占比其实有限。
- 机器太快,人才是瓶颈
即使机器的效率已经远超人类,并行多 Agent 的实际价值仍然有限。想象一下——你让一个 sub-agent 跑一个晚上,产出成果已经远超你同样时间内的产出。在这种情况下,进一步并行 5 个 sub-agent 同时跑 1 小时,意义不大。因为你的需求产出速度,跟不上机器的执行速度。机器跑完了,你还需要时间思考需求、整理结果、检查输出。
换句话说,当执行效率已经不是瓶颈时,继续堆机器数量是徒劳的。真正有价值的是多智能体拥有独立上下文的能力,是 sub-agent 架构:每个 Agent 专注单一模块、高质量交付,claude team又是next level将团队合作的反馈机制引入,说实话这是相当复杂的一件事。
这才是多智能体在日常工作中最成熟的形态。
发表回复