
这篇文章是一次真实的自我复盘——我在一场逆向工程加基础设施建设的任务里,尝试把整个流程拆成4层8步的流水线,每层有明确的输入输出契约,有验证门控,最后用 AI Skill 把整个工作流编排起来。有做对的,也有走弯路的。但更重要的是,我把整个思考过程记录下来了。
如果你也在处理复杂的多阶段任务,或者想让 AI 帮你做更靠谱的规划,这篇或许有点参考价值。
核心成功点
将一个复杂的逆向工程 + 基础设施建设任务,拆解为 4 层 8 步的流水线,每层有明确的输入/输出契约和验证门控,通过 AI Skill 编排实现半自动化工作流。
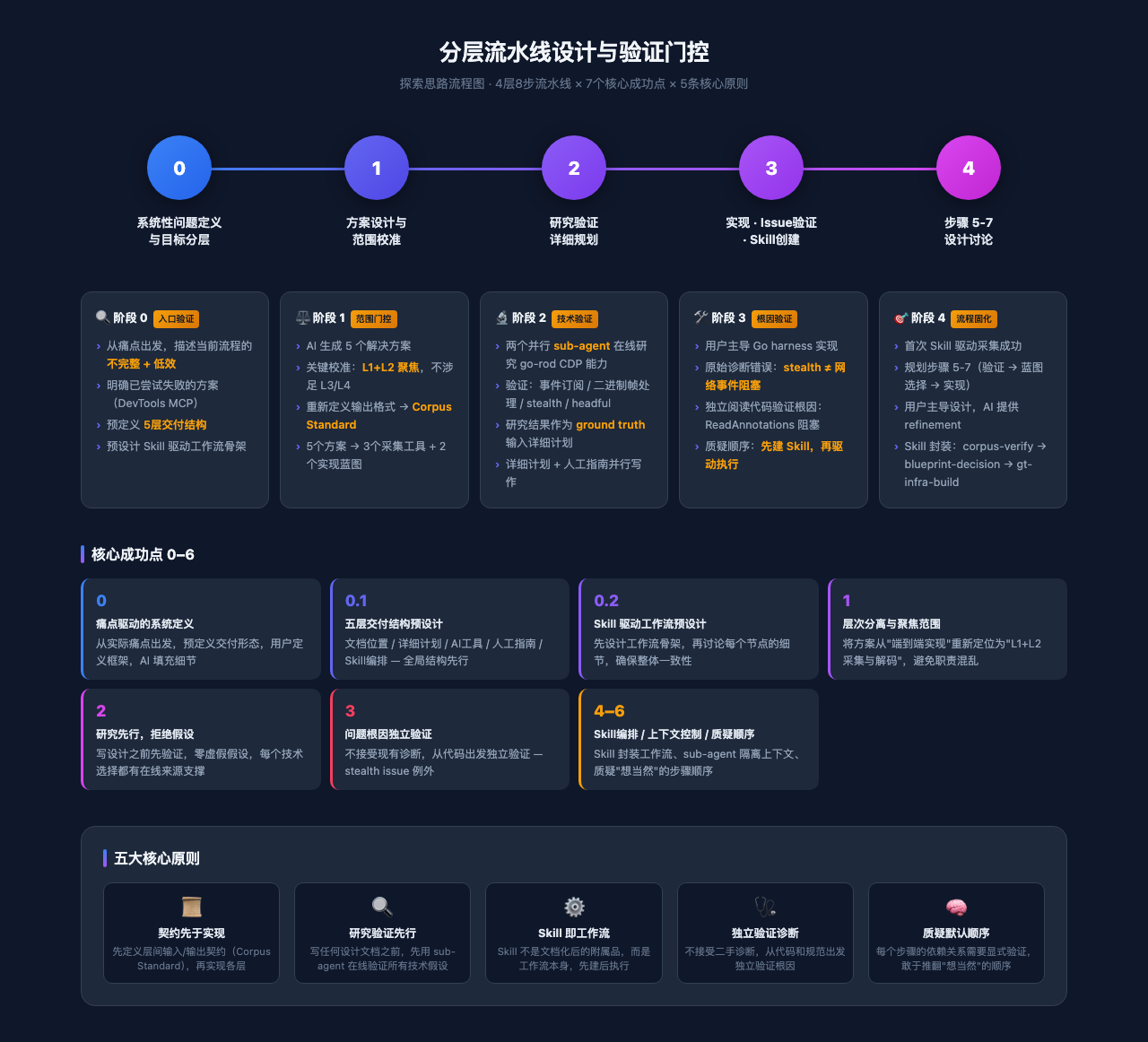
做对了什么
0. 从痛点出发的系统性问题定义
Prompt: “As a senior expert in Reverse Engineering and Network Protocol Analysis, and Quant Trading Infrastructure… Currently, I’m working around this by collecting hex binary message data and the HAR file from the web development tool manually, and provide this to AI to solve the decoding process, but the problem is that the code I collected is not complete and not efficient… I tried using the webdev tools mcp, But it’s extremely slow and it often stuck at the login process, it don’t work.”
效果: 用户没有直接说”帮我写一个抓包工具”,而是清晰描述了:(a) 当前手工流程的痛点(不完整、低效);(b) 已尝试并失败的方案(DevTools MCP 太慢/卡登录);(c) 4 个层次的目标(采集→解码→构建 agent→构建 trader)。这个问题定义直接决定了后续所有方案的设计方向——自动化采集完整数据,让 AI 看到全貌。
0.1 五层交付结构的预设计
Prompt: “now I wish to make solution 1 into detailed plan, i have drafted rough ideas of how this detailed plan plays out: 1. solution 1 related documents goes to @documents/solutions/cdp-traffic-capture 2. a detailed plan 3. tool development plan for AI to call 4. a comprehensive guide for human involvement 5. use skill-creator to create a project skill”
效果: 用户在要求详细规划之前,先提出了 5 层交付结构(文档位置、详细计划、AI 工具、人工指南、Skill 编排)。这不是让 AI 自由发挥,而是预定义了交付物的形态,AI 的工作是在这个框架内填充内容并给出优化建议。这种”用户定义框架,AI 填充细节”的协作模式贯穿整个 session。
0.2 为后续阶段预设计 Skill 驱动的工作流
Prompt: “step 5: how about create a project skill for step 5, verify decode completeness… step 7: firstly create a tool under tools/ which contains common templates… secondly create a skill called gt-infra-build that generate two detailed plan”
效果: 用户在讨论步骤 5-7 时,已经预设计了完整的 Skill 驱动工作流:corpus-verify(验证)→ blueprint decision(嵌入验证)→ gt-infra-build(规划)。每个步骤都有明确的输入/输出和 Skill 封装。这种”先设计工作流骨架,再讨论每个节点的细节”的方法确保了整体一致性。
1. 层次分离与聚焦范围
Prompt: “it is advised that these solutions are just different methods/blueprints to collect necessary key informations… L3 and L4 implementations are not the solutions’ main concern”
效果: 将 5 个解决方案从”端到端实现”重新定位为”仅关注 L1+L2 采集与解码”,避免了方案间的职责混乱。Solutions 01-03 变成纯采集工具,04-05 变成实现蓝图,每层只做一件事。
2. 研究先行,拒绝假设
Prompt: “before you write the plan or any design, it should be validated online against the relevant reliable sources using the search tools by a proper subagent”
效果: 在写 detailed-plan.md 之前,启动两个并行研究 Agent 验证 go-rod 的所有 CDP 能力(事件订阅、二进制帧处理、stealth、headful 模式)。最终计划中零虚假假设,每个技术选择都有在线来源支撑。
3. 问题根因独立验证
Prompt: “Can you validate the issue? does it really exists or is it the real cause of this issue”
效果: 发现 issue 文档中 “stealth blocks network events” 的诊断是错误的。通过阅读实际代码(stealth.go 只 patch fingerprint API,不影响 CDP Network domain),确认真正原因是 ReadAnnotations 阻塞导致 Navigate 永远无法执行。避免了基于错误诊断的修复方向。
4. 用 Skill 编排复杂工作流
Prompt: “create a project skill: cdp-capture to instruct AI to do the full workflow to complete solution 1, for the steps that require human’s action, should call human to get involved”
效果: 将 10 步工作流(构建 → 采集 → 验证 → 分析 → 审核)封装为一个 Skill,AI 驱动自动化步骤,在人工介入点暂停等待反馈。实现了”一个命令走完整个流程”的目标。
5. 渐进式交付与上下文控制
Prompt: “I would advise you to use sub-agent if possible to control the context window”
效果: 使用 4 个并行 sub-agent(2 研究 + 2 写作),将大量研究和文档生成工作隔离在子上下文中,主对话保持清晰。研究结果作为”已验证事实”传入写作 Agent,而非让写作 Agent 自己去搜索。
6. 质疑执行顺序的合理性
Prompt: “why do we have to test a platform first before creating the skill?”
效果: 推翻了”实现 → 测试 → 创建 Skill”的顺序,改为”实现 → 创建 Skill → Skill 驱动首次测试”。Skill 本身就是测试的编排器,先建后测是逻辑错误。
探索思路
阶段 0:系统性问题定义与目标分层
用户没有直接跳到”帮我写工具”,而是从三个维度定义问题:
Prompt: “Currently, I’m working around this by collecting hex binary message data and the HAR file from the web development tool manually… the problem is that the code I collected is not complete and not efficient… I tried using the webdev tools mcp, But it’s extremely slow”
关键决策:将目标拆为 4 个明确层次(L1 采集 → L2 解码 → L3 构建 agent → L4 构建 trader),并明确约束(平台无官方 API、数据通过 WS 传输、可能编码、服务部署在 Ubuntu 服务器)。这个分层直接塑造了后续所有方案的架构。
阶段 1:方案设计与范围校准
AI 生成 5 个解决方案后,用户审查并做出关键校准:
转折点: “L3 and L4 implementations are not the solutions’ main concern”
这将整个方案体系从”5 个端到端方案”重构为”3 个采集工具 + 2 个实现蓝图”,定义了清晰的层间契约(Corpus Standard)。
同时用户重新定义了输出格式:
Prompt: “the existing decode output format is just a demo, not the requirement, you can design a new format”
这催生了 07-corpus-standard.md——一个跨方案的统一输出契约。
阶段 2:研究验证 → 详细规划
选定 Solution 01(CDP)后,用户坚持”先验证再规划”:
- 两个并行研究 Agent 验证 go-rod 技术能力
- 研究结果作为 ground truth 输入详细计划
- 详细计划(999 行)+ 人工指南(445 行)并行写作
阶段 3:实现 → Issue 验证 → Skill 创建
用户独立完成 Go harness 实现,遇到问题后回来验证 issue 根因。验证发现原始诊断错误,修正后创建 Skill。
转折点: “why do we have to test a platform first before creating the skill?”
这个质疑改变了交付顺序,让 Skill 成为工作流的一等公民。
阶段 4:步骤 5-7 设计讨论
完成首次采集后,用户开始规划后续步骤(验证 → 蓝图选择 → 实现规划)。关键的设计参与:
- 用户提出 5 个初始想法
- AI 给出 refinement 建议(将工具规格合并到详细计划、推荐代码放在 tools/ 而非 documents/)
- 用户接受部分建议,保留自己的判断
使用的 Skills/Commands/Plugins/MCP
| 类型 | 名称 | 用途 |
| Skill | session-self-reflect | 归档总结本次会话 |
| Command | /compact | 压缩上下文继续长会话 |
| Command | /branch | 分支会话用于不同方案的详细规划 |
| Command | /rename | 重命名会话标记当前工作焦点 |
| Command | /effort | 调整 AI 投入级别 |
| MCP | brave-search | 在线验证技术方案可行性 |
核心原则
1. 层间契约优先于实现细节: 先定义每层的输入输出格式(Corpus Standard),再实现各层。层间通过文件格式(events.jsonl、analysis/*.md、verification-report.md)解耦。
2. 研究验证作为规划前置条件: 不写任何设计文档之前,先用 sub-agent 在线验证所有技术假设。”The memory says X exists” is not the same as “X exists now.”
3. Skill 是工作流的一等公民: Skill 不是事后文档化,而是工作流本身。先有 Skill,再用 Skill 驱动首次执行。
4. 独立验证诊断: 当遇到问题报告时,不接受现有诊断,而是从代码和规范出发独立验证根因。stealth issue 的错误诊断就是例证。
5. 并行 sub-agent 隔离上下文: 将研究和写作分离到 sub-agent,主对话只保留决策和综合判断。避免上下文膨胀。
关键成功因素
探索路径:
宏观需求 → 5 个方案(过宽)
→ 范围校准(L1+L2 聚焦)
→ Corpus Standard 定义(层间契约)
→ 研究验证 go-rod(子 Agent)
→ 详细计划 + 人工指南(并行写作)
→ Go harness 实现(用户主导)
→ Issue 验证(独立根因分析)
→ Skill 创建(工作流编排)
→ 首次采集(Skill 驱动)
→ 步骤 5-7 规划(下一层设计)可复用的方法:
- “先契约后实现”: 定义 Corpus Standard → 各 Solution 独立实现 → 实现结果都符合同一标准
- “先验证后规划”: 用 sub-agent 验证技术可行性 → 将验证结果作为 ground truth 写入计划
- “先 Skill 后执行”: 将工作流封装为 Skill → 用 Skill 驱动首次执行 → 问题在 Skill 上下文中暴露和修复
- “质疑顺序假设”: 默认顺序不一定最优,每个步骤的依赖关系需要显式验证(测试不依赖 Skill,但 Skill 才是测试的编排器)
总结
回过头看,这次最值钱的经验不是某个具体的代码方案,而是在动手之前先把验证点设计进去这个习惯。
很多团队做复杂系统,上来就开始写实现,一路狂奔,等到联调的时候才发现各种模块对不上。我以前也这样。后来学乖了:先定义层间契约,先用研究验证技术假设,遇到问题先独立验证根因——这几件事看起来是”慢”,实际上是最快的路。
具体到这次任务,有几个我认为值得坚持的点:
第一,契约先于实现。Corpus Standard 是一开始就定义的,不是因为实现完了才发现需要。层与层之间的接口清晰,出问题的概率就小很多。
第二,不接受二手诊断。issue 报告说 stealth 导致网络事件被 block,但验证之后发现根本不是这回事。直接从代码出发,独立验证,这个习惯救了我不少时间。
第三,Skill 是工作流本身,不是文档化之后的附属品。先把 Skill 建出来,再用 Skill 驱动执行。这样 Skill 本身就是测试,任何问题在 Skill 上下文里暴露和修复,效率高得多。
第四,质疑默认顺序。”实现 → 测试 → 创建 Skill” 听起来很合理,但 Skill 本身就是测试的编排器,顺序反了。敢于质疑每个”想当然”的步骤顺序,很多隐藏的问题就能提前发现。
复杂任务最怕的不是技术难度,而是方向走偏、上下文膨胀、各模块扯皮。分层流水线加验证门控,本质上是在每个关键节点都设置一个”检查站”,让错误在最早的地方被发现。这不是保守,这是让整个系统真正可持续推进的方法。
发表回复